


Deep learningで画像認識⑦〜Kerasで畳み込みニューラルネットワーク vol.3〜
前回は、KerasによるDeepLearningのモデルで、60,000枚の文字画像を用いて分類を行いました。
今回は、白血球(好中球、好酸球、単球)の顕微鏡画像(90枚)を用いて、これら3種類の分類を行います。100枚に満たないような少ない画像数でも、DeepLearningで分類可能になるテクニックや過学習を抑える方法を紹介します。
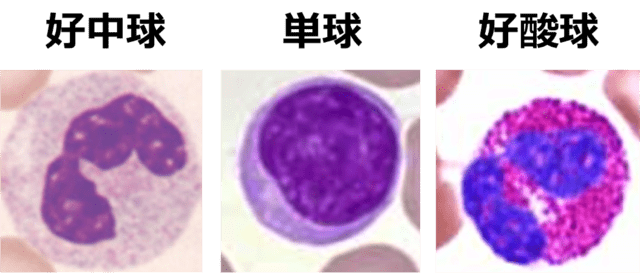
3種類の白血球(好中球、単球、好酸球)の顕微鏡画像
それぞれ30枚(計90枚)を用いてCNNによる分類を行った。
画像の水増し(Data Augmentation)
DeepLearningで画像分類というと、万単位の大量の画像を学習させる必要があるイメージがあるかもしれませんが、少ない画像数でもDeepLearningで分類が可能となる方法があります。その1つの方法が画像データの水増し(データ拡張:Data Augmentation)です。
Kerasでは、「ImageDataGenerator」というクラスが用意されており、元画像に移動、回転、拡大・縮小、反転などの人為的な操作を加えることによって、画像数を増やすことができます(もちろん、元画像によく似た画像になる点は否めないため、過学習ぎみになる不安は拭いきれません)。
下に示すように、17種類の操作項目がありますが、今回は回転や水平方向のフリップ等、3項目のみ使用しました。下に示す最初の4項目は、画像の正規化の方法を意味しており、画像の前処理としてかなり重要ですが、今回はこのクラスを使用せずに自前で正規化を行いました。各操作項目の詳細は、Keras Documentation(画像の前処理)[1]を参考にしてみてください。
from keras.preprocessing.image import ImageDataGenerator
# 画像の水増し操作
datagen = ImageDataGenerator(
featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
rotation_range=180.,
width_shift_range=0.,
height_shift_range=0.,
shear_range=0.,
zoom_range=0.,
channel_shift_range=0.,
fill_mode='nearest',
cval=0.,
horizontal_flip=True,
vertical_flip=False,
rescale=None,
dim_ordering=K.image_dim_ordering())
# 水増し画像を訓練用画像の形式に合わせる
datagen.fit(X_train)
ImageDataGenerator.pyK分割交差検証(K-fold cross-validation)
データを複数のグループに分けて交差検証(K-fold)を行うことにより、過学習(訓練用画像に特化した最適化が起きること)を抑制することができます。図2のように、例えば画像データを5つのグループに分けて、その内の1グループを検証用画像データ、残り4グループを訓練用データとします。訓練用 / 検証用データの組み合わせは5パターン選択できますので、それぞれを用いて学習させることにより、5パターンのモデルが作成されます。そして、テストデータに対し、それぞれのモデルを使って推測結果を求め、5パターンの推測結果を平均して最終的な推測結果とします。これにより、訓練用 / 検証用データの偏りによる過学習が軽減されます。
ちなみに、下記KFoldの関数内に出てくる”n_splits”を使うには、sklearnのversion0.18.1が必要なので、必要に応じてアップグレードしてください。
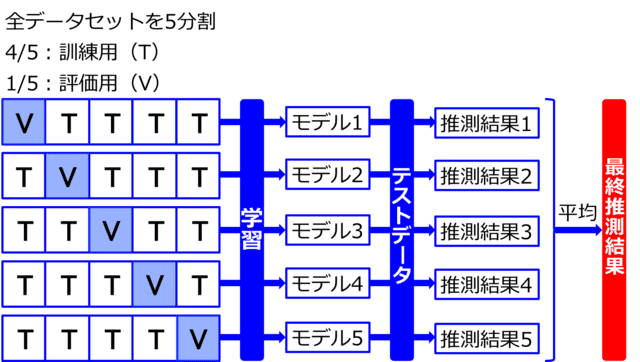
画像データセットを5分割し、4/5を訓練用、1/5を評価用として5パターンの
訓練 / 評価データの組み合わせを用いて学習を行い、5パターンのモデルを作る。
それぞれのモデルにテストデータを推測させ、
それらの推測結果の平均を最終推測結果とする。
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split
kf = KFold(n_splits=5, shuffle=True)
for train_index, eval_index in kf.split(X_train):
X_tra, X_eval = X_train[train_index], X_train[eval_index]
y_tra, y_eval = y_train[train_index], y_train[eval_index]
Kfold.pyCNNによる分類の結果
3種類の白血球画像(24-bit RGB Planar, 100×100 pixel)それぞれ30枚ずつ計90枚を訓練 / 検証に用いました。5分割のKflodを用いたため、訓練用が72枚、評価用が18枚です。これらとは別にテスト画像として12枚用意しました。
今回も前回と同じく、Kerasで畳み込みニューラルネット(CNN)のモデルを組みました。畳み込み層+プーリング層が2セットの小さなCNNです(下記のコード参照)。最適化ループを回す回数は最大50回とし、early stopping関数による過学習の抑制も行いました(patientce = 10とし、val_lossの最小値が10回更新されなければ計算ストップ)。
上述した5分割のKfoldを用いた5パターンのモデルによる推測結果の平均は以下の通りです。
(推測確率の算出には、ModelCheckpoint関数を用いて保存された、val_lossが最小となる各モデル重みを用いました。)
loss(訓練画像の損失): 0.16 accracy(訓練画像の精度):0.95
val_loss(評価画像の損失):0.23 val_accracy(評価画像の精度):0.90
評価画像を含めた精度(val_acuracy)は90%となりました(この値はあくまでも5つのモデルの平均なので、用いたモデルによっては、val_accracyが90%を超えるものや90%を下回るものもありました)。
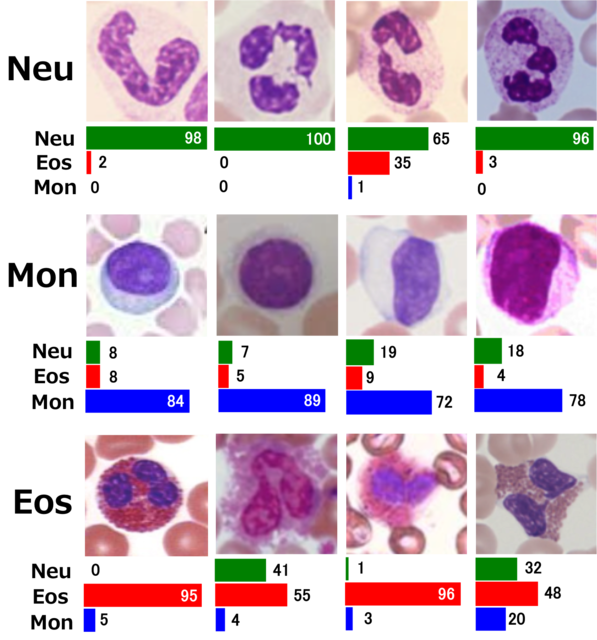
(上段)好中球(Neutrophil),
(中段)単球(Monocyte),
(下段)好酸球(Eosinophil)
のそれぞれ4つのテスト画像に対する予測確率を示す。
それぞれの値は、Kflodによって作られた5パターンのモデルそれぞれから
計算された推測確率の平均値。3種類の全てのテスト画像で、正しい推定が行われた。
訓練画像と評価画像以外のテスト画像12枚(3種類をそれぞれ4枚ずつ)を用いて、個別に予測確率を計算したものを図3に示します。テスト画像の数が少ないので統計的には何とも言えませんが、12/12 = 100(%)の確率で正しい認識を示しました。
from keras.models import Sequential
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.optimizers import RMSprop
from keras.callbacks import EarlyStopping, ModelCheckpoint
from keras.preprocessing.image import ImageDataGenerator
# 各層のパラメータ
nb_filters1 = 32 # 畳み込みフィルタ1の数
nb_filters2 = 64 # 畳み込みフィルタ2の数
nb_conv1 = 3 # 畳み込みフィルタ1の縦横pixel数
nb_conv2 = 2 # 畳み込みフィルタ2の縦横pixel数
nb_pool = 2 # プーリングを行う範囲の縦横pixel数
nb_classes = 3 # 分類するクラス数
nb_epoch = 50 # 最適化計算のループ回数
batch_size = 32 # 計算効率化のために分割された訓練データの1グループあたりのデータ数
# CNNの構成
model = Sequential()
model.add(Convolution2D(nb_filters1, nb_conv1, nb_conv1, border_mode ="same", input_shape=(3, img_rows, img_cols)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(nb_pool, nb_pool)))
model.add(Convolution2D(nb_filters2, nb_conv2, nb_conv2, border_mode ="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(nb_pool, nb_pool)))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation("softmax"))
# モデルのコンパイル
model.compile(loss="categorical_crossentropy", optimizer="rmsprop", metrics=["accuracy"])
# 過学習の抑制
early_stopping = EarlyStopping(monitor='val_loss', patience=10 , verbose=1)
# 評価に用いるモデルの保存
checkpointer = ModelCheckpoint(model_weights, monitor='val_loss', verbose=1, save_best_only=True)
# リアルタイムに水増し生成されるバッチ画像に対するモデルの適用
model.fit_generator(
datagen.flow(X_tra, Y_tra, batch_size=batch_size),
samples_per_epoch=X_tra.shape[0],
nb_epoch=nb_epoch,
verbose=1,
validation_data=(X_eval, Y_eval),
callbacks=[early_stopping, checkpointer])
CNNmodel.py今回は、KerasによるCNNモデルを用いて、白血球の顕微鏡画像の分類を行いました。
90枚という少ない枚数でも、画像の移動・変形等による画像数の水増しを行うことで、精度良くCNNで分類が可能になりました。また、KFoldと呼ばれるデータ分割交差検証によって過学習を抑制できました。(学習と評価を全てまとめたコードを次ページに載せましたので参考にしてください。)
次回も、Keras CNNによるエレガントな画像分類技術を紹介します。
【参考URL / 文献】
[1] https://keras.io/ja/preprocessing/image/
「Keras Documentation 画像の前処理」
[2] https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html, Building powerful image classification models using very little data, The Keras Blog.
[3] http://andoo.hatenablog.com/entry/finetuning_keras
[4] 実装ディープラーニング,藤田一弥, 高原 歩,オーム社.
学習に用いたコード(上:learning.py)
評価に用いたコード(下:evaluation.py)
from __future__ import print_function
import os
import struct
import numpy as np
from keras.models import Sequential
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.optimizers import RMSprop
from keras.utils import np_utils
from keras.callbacks import EarlyStopping, ModelCheckpoint
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split
from keras.preprocessing.image import ImageDataGenerator
# 各種パラメータ
nb_filters1 = 32 # 畳み込みフィルタ1の数
nb_filters2 = 64 # 畳み込みフィルタ2の数
nb_conv1 = 3 # 畳み込みフィルタ1の縦横pixel数
nb_conv2 = 2 # 畳み込みフィルタ2の縦横pixel数
nb_pool = 2 # プーリングを行う範囲の縦横pixel数
nb_classes = 3 # 分類するクラス数
nb_epoch = 50 # 最適化計算のループ回数
batch_size = 32 # 計算効率化のために分割された訓練データの1グループあたりのデータ数
img_rows, img_cols = 100, 100 # 入力画像の縦横pixel数
all_filenumber = 90 # 訓練用 & 評価用画像の数
bytesize = 3 # 画像のbyte数(24bit = 3byte)
pixelnum = img_rows*img_cols
index = 0
# 配列の確保
X_train_binary = [0 for j in range(bytesize*pixelnum*all_filenumber)]
X_train_int = [0 for j in range(bytesize*pixelnum*all_filenumber)]
y_train_int = []
# 画像&ラベルデータの読み込み
filenameX_train = "blood_total.raw"
filenameY_train = "blood_total_label.txt"
path1 = "/Users/satoshi/blood_data/"
rf1 = open(path1+filenameX_train, "rb")
rf2 = open(path1+filenameY_train, "r")
X_train_binary = rf1.read(bytesize*pixelnum*all_filenumber)
# 画像データの格納(バイナリから整数(char型)に変換して)
for i in range(bytesize*pixelnum*all_filenumber):
X_train_int[i] = struct.unpack("B", X_train_binary[i])
# ラベルデータの格納
for item in rf2:
y_train_int += list(item)
rf1.close()
rf2.close()
# numpy配列に格納
X_train = np.array(X_train_int)
y_train = np.array(y_train_int)
# 画像を4次元配列に
X_train = X_train.reshape(all_filenumber, 3, img_rows, img_cols)
# 画像を0.0~1.0の範囲に変換
X_train = X_train.astype("float32")
X_train /= 255
# 画像の前処理としての正規化
def normalization(X_train):
X_train = X_train.reshape(all_filenumber, 3*img_rows*img_cols)
for filenum in range(0, all_filenumber):
X_train[filenum] -= np.mean(X_train[filenum])
X_train = X_train.reshape(all_filenumber, 3, img_rows, img_cols)
return X_train
normalization(X_train)
# Kflodによる交差検証
kf = KFold(n_splits=5, shuffle=True)
for train_index, eval_index in kf.split(X_train):
X_tra, X_eval = X_train[train_index], X_train[eval_index]
y_tra, y_eval = y_train[train_index], y_train[eval_index]
model_weights = "/Users/satoshi/blood_data/blood_CNN_model[%d].h5" % index
index = index+1
# データの水増し(Data Augmentation)
datagen = ImageDataGenerator(
rotation_range=180,
horizontal_flip=True,
fill_mode='nearest')
# 水増し画像を訓練用画像の形式に合わせる
datagen.fit(X_tra)
# クラスラベル y (数字の0~2)を、one-hotエンコーディング型式に変換
Y_tra = np_utils.to_categorical(y_tra, nb_classes)
Y_eval = np_utils.to_categorical(y_eval, nb_classes)
# CNNのモデル
model = Sequential()
model.add(Convolution2D(nb_filters1, nb_conv1, nb_conv1, border_mode ="same", input_shape=(3, img_rows, img_cols)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(nb_pool, nb_pool)))
model.add(Convolution2D(nb_filters2, nb_conv2, nb_conv2, border_mode ="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(nb_pool, nb_pool)))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation("softmax"))
#モデルのコンパイル
model.compile(loss="categorical_crossentropy", optimizer="rmsprop", metrics=["accuracy"])
# 過学習の抑制
early_stopping = EarlyStopping(monitor='val_loss', patience=10 , verbose=1)
# 評価に用いるモデル重みデータの保存
checkpointer = ModelCheckpoint(model_weights, monitor='val_loss', verbose=1, save_best_only=True)
# リアルタイムに水増し生成されるバッチ画像に対するモデルの適用
model.fit_generator(datagen.flow(X_tra, Y_tra, batch_size=batch_size),
samples_per_epoch=X_tra.shape[0],
nb_epoch=nb_epoch,
verbose=1,
validation_data=(X_eval, Y_eval),
callbacks=[early_stopping, checkpointer])
# 評価に用いるモデル構造の保存
def save_model(model):
json_string = model.to_json()
if not os.path.isdir("cache"):
os.mkdir("cache")
json_name = "architecture.json"
open(os.path.join("cache", json_name),"w").write(json_string)
save_model(model)
learning.pyfrom __future__ import print_function
import os
import struct
import numpy as np
from keras.models import model_from_json
# 各種パラメータ
img_rows, img_cols = 100, 100
test_filenumber = 1
bytesize = 3
pixelnum = img_rows*img_cols
# 配列の確保
X_test_binary = [0 for j in range(bytesize*pixelnum*test_filenumber)]
X_test_int = [0 for j in range(bytesize*pixelnum*test_filenumber)]
test_pred = []
# テスト画像の読み込み
filenameX_test = "blood_01.raw"
path1 = "/Users/satoshi/blood_data/"
rf = open(path1+filenameX_test, "rb")
X_test_binary = rf.read(bytesize*pixelnum*test_filenumber)
# 画像データの格納(バイナリから整数(char型)に変換して)
for i in range(bytesize*pixelnum*test_filenumber):
X_test_int[i] = struct.unpack("B", X_test_binary[i])
rf.close()
# numpy配列に格納
X_test = np.array(X_test_int)
# 画像を4次元配列に
X_test = X_test.reshape(test_filenumber, 3, img_rows, img_cols)
# 画像を0.0~1.0の範囲に変換
X_test = X_test.astype("float32")
X_test /= 255
# 画像の前処理としての正規化
def normalization(X_test):
X_test = X_test.reshape(test_filenumber, 3*img_rows*img_cols)
for filenum in range(0, test_filenumber):
X_test[filenum] -= np.mean(X_test[filenum])
X_test = X_test.reshape(test_filenumber, 3, img_rows, img_cols)
return X_test
normalization(X_test)
# 保存したモデル重みデータとモデル構造の読み込み
for index in range(0,5):
model_weights = "/Users/satoshi/blood_data/blood_CNN_model[%d].h5" % index
json_name = "architecture.json"
model = model_from_json(open(os.path.join("cache", json_name)).read())
model.load_weights(model_weights)
# 各モデルにおける推測確率の計算
test_pred.append(model.predict(X_test))
test_average = np.array(test_pred[0])
# 5種類のモデルの推測確率の平均
for i in range(1,5):
test_average += np.array(test_pred[i])
test_average /= 5
print(test_average)
evaluation.py

{kind=link}
{kind=link}