

Deep learningで画像認識⑥〜Kerasで畳み込みニューラルネットワーク vol.2〜
前回は、KerasでDeepLearningを行うための準備(画像データの読み込みや前処理)を行いました。
今回は、実際に畳み込みニューラルネットワーク(CNN)で画像データを分類してみます。
MNISTというサイトからダウンロードした60000個の手書き文字を学習した後、自分が書いた手書き文字を認識できるかどうか試してみます。
CNNのモデルの組み立て
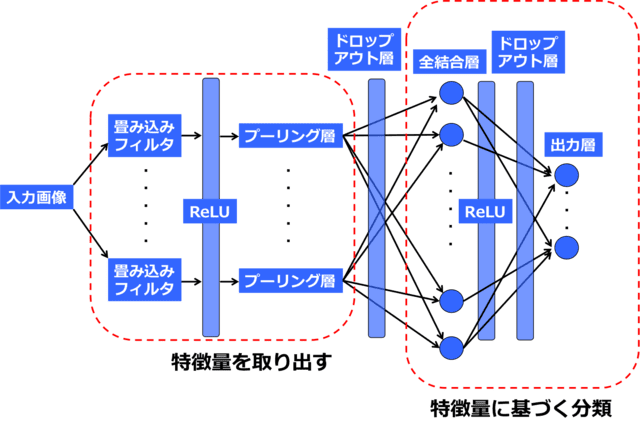
この図をKerasのコマンドで表すと下のようになります。
たった数十行で簡単なDeepLearningの出来上がりです。
from keras.models import Sequential
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.layers.core import Dense, Dropout, Activation
from keras.optimizers import Adadelta
from keras.callbacks import EarlyStopping
# 各層のパラメータ
nb_filters = 10 # 畳み込みフィルタ数
nb_conv = 3 # 畳み込みフィルタの縦横pixel数
nb_pool = 2 # プーリングを行う範囲の縦横pixel数
nb_classes = 10 # 分類するクラス数
nb_epoch = 50 # 最適化計算のループ回数
# 特徴量抽出
model = Sequential()
model.add(Convolution2D(nb_filters, nb_conv, nb_conv) # 畳み込みフィルタ層
model.add(Activation("relu")) # 最適化関数
model.add(MaxPooling2D(pool_size=(nb_pool, nb_pool))) # プーリング層
model.add(Dropout(0.2)) # ドロップアウト層
# 特徴量に基づいた分類
model.add(Flatten()) # 全結合層入力のためのデータの一次元化(図1では省略している)
model.add(Dense(128)) # 全結合層
model.add(Activation("relu")) # 最適化関数
model.add(Dropout(0.2)) # ドロップアウト層
model.add(Dense(nb_classes)) # 出力層(全結合層:ノードの数は分類クラス数)
model.add(Activation("softmax")) # 出力層
#モデルのコンパイル
model.compile(loss="categorical_crossentropy", optimizer="adadelta", metrics=["accuracy"])
# モデルの学習
early_stopping = EarlyStopping(patience=2, verbose=1)
model.fit(X_train, Y_train, nb_epoch=nb_epoch, batch_size=128, verbose=1, validation_split=0.2, callbacks=[early_stopping])
# モデルの評価
classes = model.predict(X_test, batch_size=128, verbose=True)
print(classes[0])
CNNmodel.pyモデルの最適化(学習)方法
モデルの最適化アルゴリズムには”adadelta”というものを用いました。他の最適化アルゴリズムとしてSGD, Adam, RMSprop等を用いることができます。
60000枚の画像データの内、8割(48000枚)を訓練用、2割(12000枚)を評価用として用いて学習(最適化)を行いました。訓練用の画像だけで学習するとそれにどんどん最適化して過学習してしまいます。CNNの目的は、まだ見たことのない画像を正確に評価することなので、訓練用の画像以外の画像情報(評価用画像)を踏まえた上で最適化される必要があります。この収束判定を自動で行ってくれるのが、early stopping関数で、評価用データを用いた最適化計算が収束したら予測精度が下がる前に計算ループを止めてくれます。
early_stopping = EarlyStopping(patience=2, verbose=1)
model.fit(X_train, Y_train, nb_epoch=nb_epoch, batch_size=128, verbose=1, validation_split=0.2, callbacks=[early_stopping])
# patientce:何回連続で損失の最小値が更新されなかったらループを止めるか
# verbose:コマンドラインにコメントを出力する場合は"1"と設定
# batch_size:計算効率化のために分割された訓練データの1グループあたりのデータ数
# validation_split:全ての画像の内、評価画像として用いる割合(0.2なら最後の20%)
learning.pyCNNの実行結果
図2に、学習の経過を表すコメントの出力を示します。最適化によって、評価画像の精度(accuracy)が98.4%、損失(loss)が0.0537となり高い精度で学習が行われたことがわかります。また、図3に示すように、50回の最適化計算ループを回した結果、訓練画像のlossは減少しつづける一方で、評価画像のlossは徐々に収束している様子が分かります(実際には、early stopping関数により30回で最適化ループは打ち切られました)。
図2中の下方に、入力画像が0~9の数字である予測確率が順に記されており、図2の手書き数字 “8”をテスト画像として入力した場合、それが”8″である確率は0.9997、“8”以外である確率はどれも0に近い値になっています。

最適化ループ1回毎に訓練画像、評価画像の精度(accuracy)と損失(loss)の値が表示されている。early stopping関数により30回で最適化ループは打ち切られた。一番下に、各数字(0~9)の予測確率が出力されている。

訓練画像の損失(loss)は最適化ループを繰り返すほど減少しているが、評価画像の損失(val_loss)は収束する傾向が見られた。
試しに、何種類かの手書き数字をテスト画像として入力してみました(28×28のバイナリデータ)(図4)。認識しやすい入力画像” 8″ においては正しく認識されましたが(予測確率99.97%)、形を崩した紛らわしいテスト画像に関しては、少しの変化に予測結果が大きく揺れる傾向が見られました(下段)。私の目には、図4下段はどれも”9″に一番近いように見えますが、CNNの予測結果は全く予想を裏切りました。
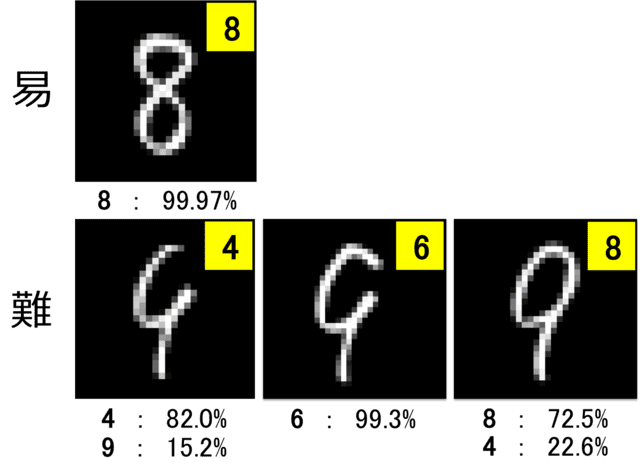
テスト画像とその予測結果(右上の黄色内の数字)を示す。画像下の数字は、それぞれの数字の予測確率を表す。認識しやすいテスト画像においては正しく認識された(上)、一方紛らわしい入力画像に関しては、少しの違いに対して予測結果が揺れる傾向が見られた(下)。
このように、簡単にモデルが組み立てられてて、計算結果もすぐに出るので、Kerasはなかなか使いやすいです。今回は、Kerasを用いた畳み込みニューラルネットワークのモデルで、手書き文字認識を行いました。MNIST画像データの読み込みと前処理については、下記の[1]を参照してください。
次回もKerasを使った面白い画像分類の例を紹介します。
【参考URL】
[1] https://lp-tech.net/articles/gjZvu
<Deep learningで画像認識⑤〜Kerasで畳み込みニューラルネットワーク vol.1〜>
[2] http://aidiary.hatenablog.com/entry/20161109/1478696865


{kind=link}