

Deep learningで画像認識⑤ 〜Kerasで畳み込みニューラルネットワーク vol.1〜
Kerasとは?
Kerasと呼ばれるDeep Learingのライブラリを使って、簡単に畳み込みニューラルネットワークを実装してみます。
世の中に出回っている機械学習のライブラリには、いくつか種類があります。
・Tensorflow (開発元:Google)
・Theano (開発元:モントリオール大学)
・Caffe(開発元:Berkeley Vision and Learning Center)
これらは、python向けのDeep Learningのライブラリを持っています。今回は、Kerasと呼ばれる最近開発されたDeep Learningのライブラリを使って、文字認識のニューラルネットワークを組んでみようと思います。
Kerasは、先述したTheanoとTensorflowが内部で使われており、容易に両方を切り替えて使うことができます。また、レゴブロックを組み合わせるようにコマンドを当てはめていくだけでDeep Learningのモデルを作ることができます。ただ、内部でTheanoやTensorflowによって行われている処理がブラックボックスなため、動作原理まで遡って理解することが難しいという欠点はあります。
「出来るだけ多くの人にDeep Learningに触れてもらいたい」という理念の元、googleで開発されました。
Kerasのインストール
① Git HubからKerasをダウンロードします。
② ダウンロードしたフォルダに入って、
sudo python setup.py install とコマンドを打ちます。
以上で、インストール完了です。
デフォルトでは、内部で動くライブラリがTensorflowになっていますが、Theanoへの切り替えも可能です(https://keras.io/backend/を参照)。
MNISTとは
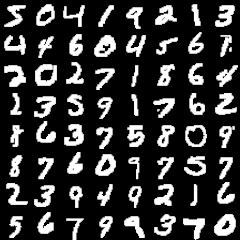
さて、今回行う文字認識ですが、MNISTという有名な手書き文字のデータセットがあります。トレーニング用の60,000個のデータとテスト用の10,000個のデータが入手できます。
ここでは、まずトレーニング用のデータだけダウンロードします。
トレーニング用画像データ:train-images-idx3-ubyte
トレーニング用ラベルデータ:train-labels-idx1-ubyte
トレーニング用画像データは、28×28ピクセルのグレースケールの画像データで、unsigned char型のバイナリファイルになっています(ヘッダが16byte)。トレーニング用ラベルデータは、それぞれの画像が表す数字(正解)が記されており、これもunsigned char型のバイナリファイルで取得できます(ヘッダが8byte)。
ちなみに、下記のコマンドで、MNISTの画像データやラベルデータをバイナリデータから0~255の整数値が羅列されたtxtデータに変換することもできます(下図参照)。
<画像データ>
od -An -v -tu1 -j16 -w784 train-images-idx3-ubyte | sed ‘s/^ *//’ | tr -s ‘ ‘ >train-images.txt
<ラベルデータ>
od -An -v -tu1 -j8 -w1 train-labels-idx1-ubyte | tr -d ‘ ‘ >train-labels.txt
(ちなみにMac OS Xでは、-wがサポートされていないバージョンがあるので、適宜-w784や-w1を省いてください)

バイナリ画像ファイルの数字の領域に、txtファイルで画素値(0~255)が羅列されているのが分かる(左図は、数字の「5」)
MNISTデータ読み込みと前処理
Kerasには、このMNISTの文字データをwebからダウンロードして配列に格納するモジュールがあらかじめ用意されており、下記のたった1行でそれを行うことができます。(~/keras/examples/mnist_cnn.py 参照)
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train:トレーニング用の画像データの配列
X_test:テスト用の画像データの配列
y_train:トレーニング用のラベルデータの配列
y_test:テスト用のラベルデータの配列
とても便利で素晴らしいのですが、今回は敢えて画像データを読み込んで配列に格納するところを自作してみました。画像データの読み込みと前処理を下記のコードに記します。
これでDeep Learingの準備が整いました。
次回は、Deep Learingのモデルを作り、自分で書いた手書き文字を判別させてみます。
from keras.datasets import mnist
from keras.utils import np_utils
import numpy
import struct
import math
# 画像のパラメータ
train_filenum = 60000
test_filenum = 1
img_rows, img_cols = 28, 28
pixelnum = img_rows*img_cols
bytesize = 1
nb_classes = 10
# 配列の確保
X_train_binary = [0 for j in range(pixelnum*train_filenum)]
X_train_int = [0 for j in range(pixelnum*train_filenum)]
X_test_binary = [0 for j in range(pixelnum*test_filenum)]
X_test_int = [0 for j in range(pixelnum*test_filenum)]
y_train_int = [0 for j in range(train_filenum)]
y_test_int = [0 for j in range(test_filenum)]
# ダウンロードしたトレーニング画像を開く
f1 = open("train-images-idx3-ubyte", "rb")
f2 = open("train-labels-idx1-ubyte", "rb")
# 自分で手書き作製したテスト画像(今回は数字の8)を開く
f3 = open("test-images_sample_8", "rb")
f4 = open("test-labels_sample_8", "rb")
# 画像データ読み込み
f1.seek(16)
X_train_binary = f1.read(bytesize*img_rows*img_cols*train_filenum)
X_test_binary = f3.read(bytesize*img_rows*img_cols*test_filenum)
f1.close()
f3.close()
# ラベルデータ読み込み
f2.seek(8)
y_train_binary = f2.read(bytesize*train_filenum)
y_test_binary = f4.read(bytesize*test_filenum)
f2.close()
f4.close()
# バイナリを整数(char型)に変換
for a in range(img_rows*img_cols*train_filenum):
X_train_int[a] = struct.unpack("B", X_train_binary[a])
for a in range(img_rows*img_cols*test_filenum):
X_test_int[a] = struct.unpack("B", X_test_binary[a])
for a in range(train_filenum):
y_train_int[a] = struct.unpack("B", y_train_binary[a])
for a in range(test_filenum):
y_test_int[a] = struct.unpack("B", y_test_binary[a])
# numpy配列に格納
X_train = numpy.array(X_train_int)
X_test = numpy.array(X_test_int)
y_train = numpy.array(y_train_int)
y_test = numpy.array(y_test_int)
# 画像を一次元配列に
X_train = X_train.reshape(train_filenumber, 1, img_rows, img_cols)
X_test = X_test.reshape(test_filenumber, 1, img_rows, img_cols)
# 画像を0.0~1.0の範囲に変換
X_train = X_train.astype("float32")
X_test = X_test.astype("float32")
X_train /= 255
X_test /= 255
print(X_train.shape[0], "train samples")
print(X_test.shape[0], "test samples")
# クラスラベル y (数字の0~9)を、one-hotエンコーディング型式に変換
Y_train = np_utils.to_categorical(y_train, nb_classes)
Y_test = np_utils.to_categorical(y_test, nb_classes)