

Deep learningで画像認識① 〜Deep Learningとは?〜
最近、様々な分野でDeep learningと呼ばれる技術が用いられています。Deep learningとは、人間の脳の神経細胞のネットワーク(ニューラルネットワーク)を模倣した情報処理技術です。Deep learningでは、層が深い(ディープな)ニューラルネットワーク(多層ネットワーク)を組むことによって、画像や音声などに含まれる特徴量をコンピューター自身が発見し、分類のルールを構築することが可能になりました。
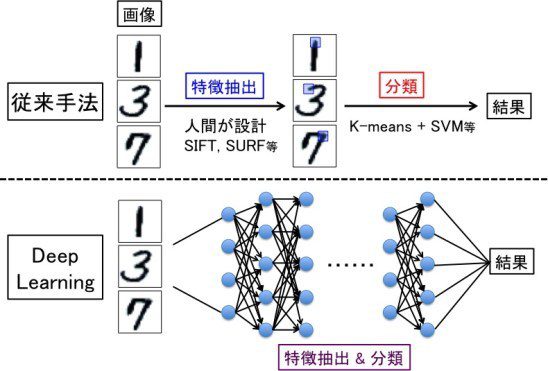
従来は、人間がまず特徴量を設定し、その後、その特徴量を基に分類アルゴリズムにかけて分類するという手法でしたが、Deep learningにより、人間による特徴量の設定の必要なくデータ分類が可能になったことは、機械学習技術における根本的な変化です(図1)。
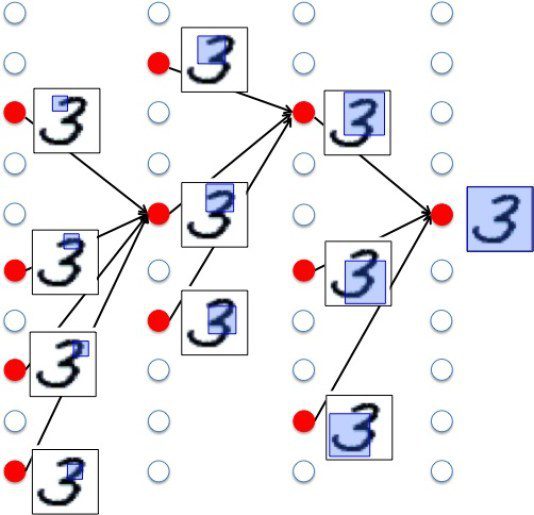
Deep learningを用いた画像認識では、この多層ネットワークの「層」に対応して画像の特徴が学習されます。例えば、数字の手書き文字「3」を画像データとして入力したとしましょう。浅い層(左側)では、「3」の小さい特徴が認識され、層が深くなるにつれて、小さい特徴が組み合わされ、「3」の大きな特徴が認識されます(図2)。
このようにして、大量の様々な手書きの「3」の画像を入力し、それが数字の「3」というものであることを教えて学習させていくと、どのような手書きの「3」にも共通して反応するユニットが生成されてきます(特に右側に近い層において)。こうして、どのような手書きの「3」にも共通する特徴が学習されていき、今まで入力されたことのない手書きの「3」が入力されたとしても、数字の「3」だと認識し、分類が可能となります。
また、You tube上にある大量の画像データをDeep learningの多層ネットワークに入力し学習させることによって、ヒトやネコの顔などの特定の物体だけに選択的に反応するユニットが自然に生成されることがスタンフォード大学とGoogleの研究チームにより示されました(2014年)[1](図3)。これも、上の手書き文字の例と同様、層の浅いところでは、線分などの小さい特徴が認識され、層が深くなるにつれて、より広範囲の特徴が認識されるようになるためです。
ちなみに、この研究で用いられたDeep learningのネットワークの層数は22層になります。層を多く積み重ねることにどういう意味があるのか、またこれらのネットワークは入力画像の何を「見ている」のか等の根本的な疑問には、まだ明確な答えはありません。
しかし、Deep learningを用いた画像認識はまさに、私たちが文字やヒトやネコを認識する時に用いている視覚的な「概念」(同類の物のそれぞれの表象から共通部分をぬき出して得た表象)をコンピューターが学習により得ている、ということは確かです。
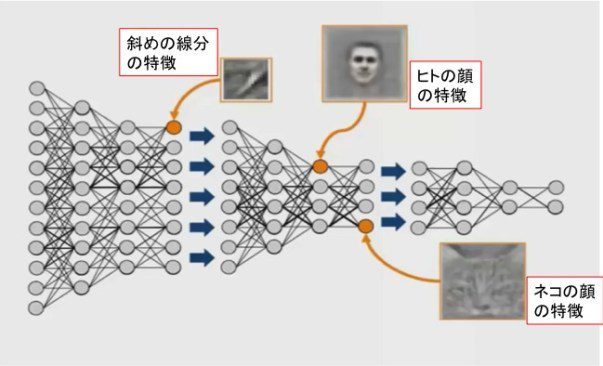
(ヒトやネコの顔に反応するユニットが出現する)
このDeep learningの技術を用いて、医療で用いられる画像データ(医用画像)から病気を判定することも可能になってきています。医用画像にはレントゲン写真、MRI、CTスキャン、顕微鏡写真などがあります。解析を行う前に、大量の医用画像データをDeep learningのネットワークに入力し学習させ、診断したい患者の画像データの「特徴を抽出し分類する」ことによって、画像中に悪性腫瘍などが存在する確率を高速に推定することが可能になります(図4)。
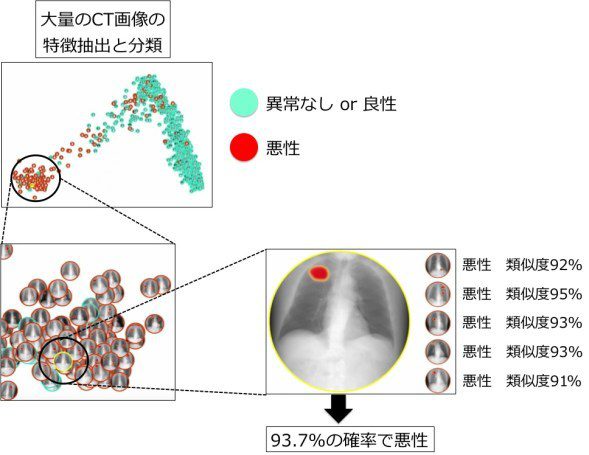
放射線科医や病理医1人あたりに診断しなければならない検査画像は、年々増加しています。また、診断の難しい疾患になればなるほど、読影のスキルも必要になるため、医師1人当たりの負担はより大きくなり、見落としや見間違いも増える可能性があります。今後、豊富な医用画像データ量を活かしたDeep learningによる画像診断により、医師の負担を減らし、より安全で高精度な画像診断が進んでいくことが大いに期待されます。
このように、Deep learningは画像認識の分野で大きな成功を収めています。画像認識で主に用いられるDeep learningの多層ネットワークは、畳み込みニューラルネットワーク(CNN:Convolutional Neural Network)と呼ばれます。次回は、このCNNについて詳しく紹介します。
【参考URL】
[1] http://www.cs.unc.edu/~wliu/papers/GoogLeNet.pdf
[2] http://www.slideshare.net/ktrnkym/ai-tool-introduction-20140710b
[3] http://www.enlitic.com/science.html#deep-learning
[4] http://lp-tech.net/archives/1312