

Deep learningで画像認識③ 〜ネオコグニトロンとは?〜
Deep learningは、画像認識において大きな成功を収めています。そこで用いられる多層ネットワークは、畳み込みニューラルネットワーク(convolutional neural network:CNN)と呼ばれており、画像認識に適した独特の構造を持っています。
前回(Deep learningで画像認識②)は、CNNがなぜ画像認識に適しているのかを解説しました。簡単にまとめると、CNNが、われわれの視覚野の神経細胞の2つの働き
①「画像の濃淡パターンを検出する(特徴抽出)」:単純型細胞(以下S細胞)
②「物体の位置が変動しても同一の物体であるとみなす(位置ズレを許容する)」:複雑型細胞(以下C細胞)
これらを組み合わせたモデルになっているからです。
この2つの神経細胞の働きを組み込んだ、CNNの初期のモデルは、「ネオコグニトロン」と呼ばれ、日本人研究者の福島邦彦氏が1982年に発表しました。ネオコグニトロンは、「特徴抽出を行うS細胞層」と「位置ズレを許容するC細胞層」を交互に多層に接続した構造をとっています(図1)。
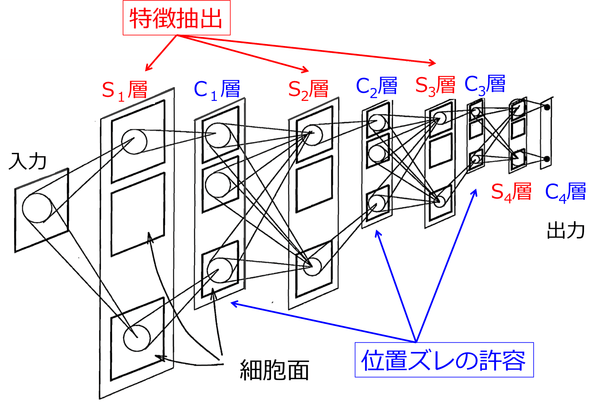
(図は文献[1]を参照)
まず、「特徴抽出を行うS細胞層」から見ていきましょう。
図1の各層は、それぞれ複数の細胞面から構成されており、同じ細胞面内のS細胞は、同じ入力パターンに反応するように構成されています。つまり、それぞれのS細胞は、同じ特徴を抽出しますが、その特徴を抽出してくる受容野の位置(ここでは前層のC細胞面での位置)が異なるのです(図2)。
そして、細胞面内の全てのS細胞がC細胞層からの同じ入力パターンに反応する(つまり同じ結合パターンで結合している)ということは、まさにC細胞面に空間フィルタをかける(畳み込む)処理を行っていることになります。このC-S細胞面間の結合パターンは、学習によって変化し、それはつまり、畳み込みフィルタが学習によって変化することを意味しています。
そして学習が終了すれば、畳み込みフィルタは最適化され、それぞれのS細胞は、結合している前層のC細胞の反応パターンの特徴の1つに選択的に反応するようになります。このようにして、それぞれのS細胞面での特徴抽出が行われることになります。
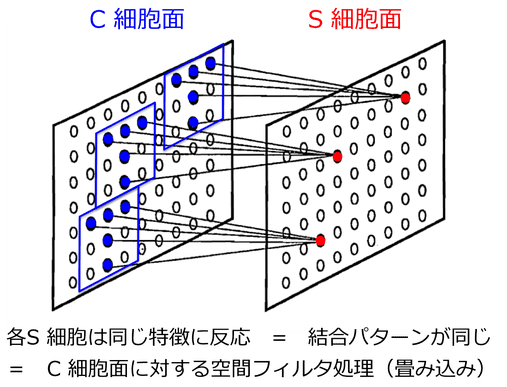
(図は文献[1]を参照)
次に、「位置ズレを許容するC細胞層」について見てみましょう。
C-S細胞面間の結合パターンが学習によって変化するのに対し、S-C細胞面間の結合は固定されています。C細胞は、S細胞面での位置がわずかに異なるS細胞からの信号を固定結合によって集めて(二乗平均をとって)反応を起こします。
この平均化操作は、S細胞での反応を空間的にぼかす効果を持ちます。別の言い方をすれば、「S細胞面での反応位置の影響をシビアに受けることなくC細胞が反応できる」、ということになります。ちなみに、CNNでは、固定結合しているS細胞面から最大値を選択する(Max pooling)によってこの平均化操作を行っています。
このように、ネオコグニトロンにおいて、「C-S細胞面間における特徴抽出」と「S-C細胞面間における反応位置ズレの許容」を繰り返すことによって、入力パターンの位置ズレやサイズ変化の影響をあまり受けずに、形の違いのみに反応(特徴抽出)できるため、頑強なパターン認識が可能になります。
結論は、繰り返しになりますが、
■ネオコグニトロンのC-S細胞面間での可変結合パターン最適化が、CNNにおける畳み込みフィルタ最適化と同じ意味を持ち、
■ネオコグニトロンのS-C細胞面間の固定結合におけるS細胞からの信号の二乗平均をとる操作が、CNNにおけるMax poolingによる平均化処理と同じ意味(位置ズレの許容)を持ちます。
では、ネオコグニトロンとCNNの違いはどこにあるのでしょうか?
違いは、学習(最適化)の方法だけです。
ネオコグニトロンは、「add-if silent」という学習方法を用いているのに対し、CNNは誤差逆伝播法(back propagation)などを用いています(詳細は文献[2]参照)。実際、ネオコグニトロンの学習方法に、誤差逆伝播法に基づく勾配降下法を適用したもの(LeNetと呼ばれる)は、現在のCNNと基本的な要素は全て同じであり、文字認識のタスクにおいて高い性能を達成しています。そして更なる計算機の発展によって、ネオコグニトロンは、今CNNとして、画像認識において花開いているわけです。
次回は、このネオコグニトロンに端を発したCNNを使って実際に文字認識を行ってみます。
【参考URL】
[1] 視覚情報の統合過程に関する基礎的研究
[2] Deep CNN ネオコグニトロンの学習